

让应用支持全球的各种语言是一项挑战。兼容不同的语言形态、语法、数据格式需从设计层面就开始考量。遗憾的是,我们很容易忽略使用其他语言或文字系统的用户,从而使得体验受损,甚至造成用户流失。
设计支持全球语言的 UI 的重要性主要体现在以下 3 个方面:
①提升用户体验
支持本地语言的 UI 能提升用户粘性,这对于提升用户体验和用户增长非常重要。
②提升品牌全球影响力
通过支持全球语言,可以打造更具全球影响力的品牌,提升品牌的全球认知度。
③推动科技向善
引导大家关注处于文化弱势困境的群体,让所有人均可平等地享受科技带来的便捷,实现「为所有人设计」的目标。
可见,设计支持全球语言的 UI 是至关重要的。因此,我们建议将支持全球语言纳入到日常设计的考量范围内。
本文将从文本翻译、文本排版、数据格式等 3 个方面,带领读者对多样的语言环境进行初步了解,并介绍相应的最佳设计实践。
一、文本翻译
文本翻译是支持多语言的第一步,也是最为重要的一步。通常,这部分工作主要都由专职的翻译人员来完成。但为了保证翻译质量,我们还需尽可能做到以下 4 点:
- 分离文本、代码
- 分离文本、图像
- 添加文本注释
- 创建翻译指南
1. 分离文本、代码
将需要本地化的 UI 文本从代码中分离出来,以独立的资源文件方式存放,以备交付给本地化人员进行本地化处理。
我们可以在 Xcode 中使用 string catalog 来管理 UI 文本。
2. 分离文本、图像
对于包含文本的图像,为每个语言都提供一个独立的素材,不仅成本高,还会增加应用的内存占用。因此,UI 文本应与文本分离。
我们可以将这类图像上的文本与图像本身分层,以达到简单替换字符串即可完成翻译的效果。
3. 添加文本注释
为 UI 文本添加注释(comments)可以为翻译人员提供必要的信息,从而协助他们翻译出清晰且自然的译文。
注释可以包含以下 2 类内容:
①显示位置
描述文本会显示在什么 UI 元素上,例如:
Text("收藏", comment: "按钮")
Text("收藏", comment: "导航栏标题")
②上下文
在上面的案例中,尽管已知晓文本的显示位置,但翻译人员可能还是无法知晓「收藏」的具体含义。其可能是「Add to Favorites」,也可能是「Favorites」。因此,注释有时还需要添加上下文,如:
Text("收藏", comment: "按钮: 收藏此项目")
Text("收藏", comment: "按钮: 前往已收藏项的列表")
4. 创建翻译指南
通过以上设计策略,翻译的准确性已有所保证。但为了让译文更清晰、自然,我们还需创建翻译指南。例如,淘宝的翻译人员就需要从翻译指南中了解「亲」这一用词的来源及含义。
翻译指南主要包括以下 2 部份内容:
①风格指南(Style Guide)
风格指南包含了产品的行文语气、写作风格、句子结构、拼写等规则。其并非充满语言规则的语法手册,而是帮助翻译人员产出更佳译文的工具。
②术语表(Glossary)
术语表包含了产品经过考量的特定翻译,以帮助翻译人员保证翻译的一致性。
二、文本排版
不同的语言有不同的展现形式。因此,我们需要提供能灵活变化以优雅展示内容的 UI。
制定文本排版策略应主要考虑以下 5 点:
- 字符形态
- 词汇分隔
- 文本长度
- 文本强调
- 缩写
1. 字符形态
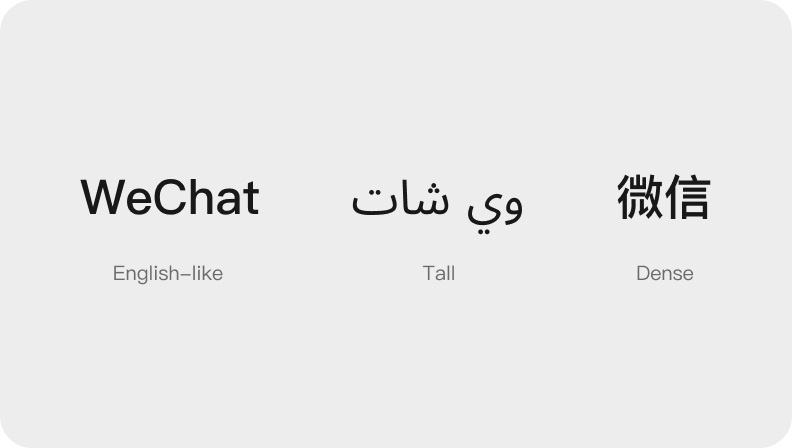
不同的语言通常使用不同的字符(glyph),其可以被分为以下 3 类:
①English-like
用于欧洲、非洲的大部分语言(如英语、希腊语、西里尔语、希伯来语、亚美尼亚语、格鲁吉亚语等)的字符类型。
②Tall
用于南亚、东南亚语言(如阿拉伯语、印地语、泰卢固语、泰语、越南语等)的字符类型。
③Dense
用于中文、日文、朝鲜文的字符类型。
与拉丁字母的相比,tall、dense 类型的字符在视觉上显得更复杂,如:
- 一些语言会在字符上方、下方添加重音符号(diacritic marks)、变音符号(accent marks)。如法语中的「père」。
- 泰语的元音字母(vowels)写在辅音字母(consonants)的上方、下方、左侧、右侧。如「อยู่ที่ไหน」。
不仅如此,tall 类型的字符还容易出现文本被裁切的现象。

可见,应为使用较为复杂的字符的文本提供更大的行高、行间距,或更大的字号,以确保可读性。
我们也可以利用 UIKit 的「dynamic line-height adjustments」,以自动优化 tall 类型的字符的行高。
2. 词汇分隔
词汇分隔指的是,用特定的符号或空格将不同的词或词组分隔开来,使其更易于理解。例如,在英语中,我们通常在单词之间使用空格来分隔它们。
对于没有明显的词汇分隔的语言(如汉语、日语),一个单词常常被拆分到 2 行中。当此现象出现在标题文本中时,拆分的单词会增加读者的识别、理解成本。
为确保良好的可读性,应尽可能避免在标题中拆分单词。
我们也可以利用 UIKit 的「improved line breaking」,以自动优化汉语、日语、韩语的换行行为。

3. 文本长度
将内容翻译成不同语言时,译文的长度可能会有非常大的变化。
以下是「200 次浏览」中的「次浏览」在翻译成不同语言后的长度变化:

可见,翻译后的 UI 文本可能会面临显示空间不足或页面空白过多的问题。
以下是从英语翻译到欧洲语言的平均预期扩展率:
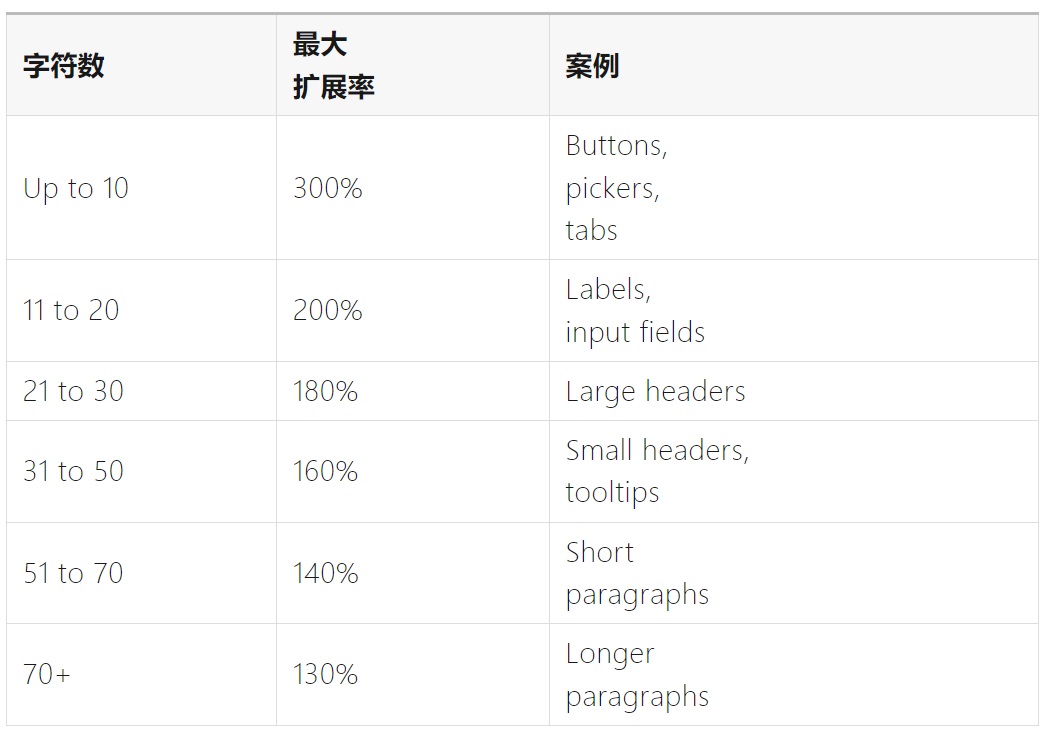
可见,较短的文本字段更易受到文本扩展的影响。
值得注意的是,文本扩展关注的是「文本长度」的变化,而不是「字符数」的变化。因为,汉语、日语的字符所需的水平空间一般都比拉丁字母大得多。例如,英文中的「desktop」在日文中写为「デスクトップ」,虽然日文的字符数少了 1 个,但所需的水平空间却大了很多。
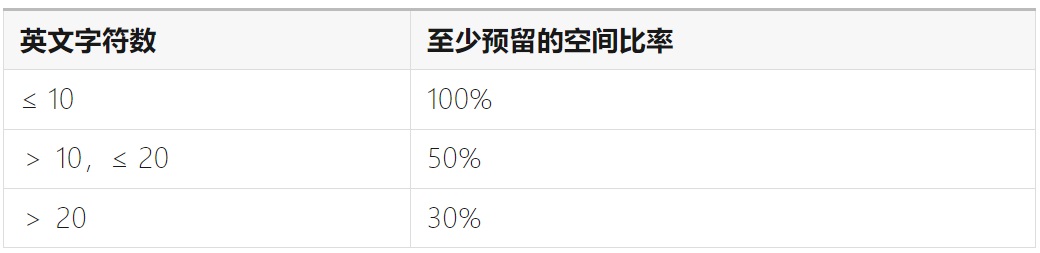
①设计策略
以英语为基准,按以下表格提供的比率来设定显示空间。
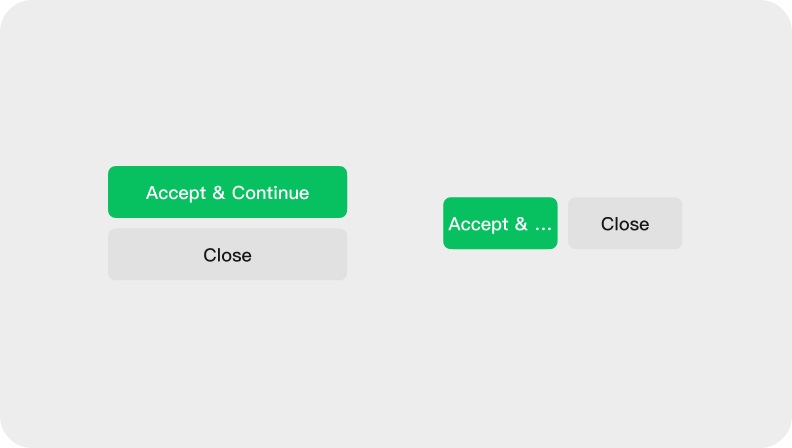
优先纵向排布含文本图层的元素。
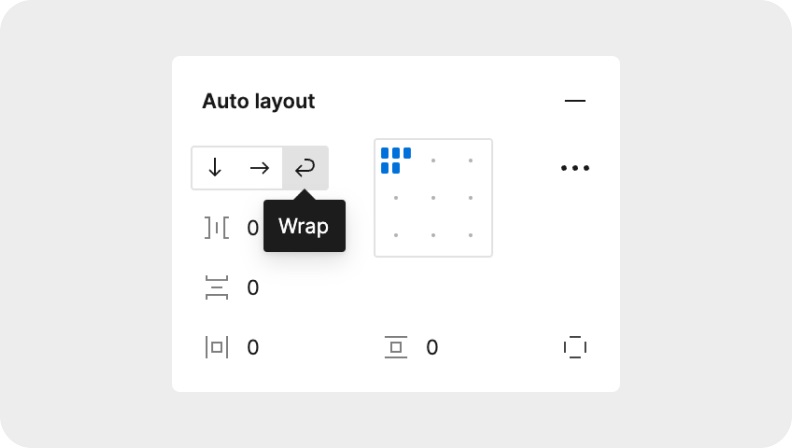
若需要水平排布元素,尽可能减少每一行的元素数量。
水平排列的元素可以通过自适应向垂直方向扩展。在 Figma 中,将 auto layout 的 direction 设为「warp」。
对于文本溢出的场景,可按需选择省略、换行、折叠(渐进展示)、滚动(跑马灯效果)等策略
- 若选用省略的策略,需要评估省略号前展示的内容是否可被理解。在 Figma 中,为文本图层开启「truncate text」。
- 若选用换行的策略,需要进一步明确极限行数,以保证容器高度可控。在 Figma 中,为文本图层开启「truncate text」并设定「max lines」。
- 若选用滚动的策略,需要评估是否会过度吸引注意力。
4. 文本强调
一些语言不适合使用粗体(bold)和斜体(italics)来强调文本。例如,中文、日文可以通过加粗来进行强调,却通常不用斜体,因为它们缺乏斜体字形。

此外,一些语言不适合使用下划线,如字符自带基线的天城文。
可见,应慎用粗体、斜体、下划线等字符样式。
5. 缩写
避免使用缩写来规避文本扩展的影响。因为,对于许多语言(如阿拉伯语、俄语),缩写并不常见。此外,缩写本身常常就是难以理解的。
三、读写方向
不同的语言通常使用不同的读写方向,其一般被分为以下 2 类:
①LTR Languages
全称为「left-to-right languages」。如基于拉丁字母(如英语、法语等)、西里尔字母(如俄语、保加利亚语等)、方块字(如汉语、日语等)的语言。
②RTL Languages
全称为「right-to-left languages」。如阿拉伯语、波斯语、乌尔都语、希伯来语、意第绪语、迪维西语等语言。
此外,还有中文、日文、韩文的传统垂直读写方向。对此,本文暂不展开讨论。

支持多读写方向不仅仅是简单地更改对齐方式、进行镜像翻转。我们需要将 UI 元素分为以下 3 类来分别处理:
1. Mirrored
其包含 2 类:
①需要镜像翻转整体的元素类型,例如:
传达水平方向的图标

需要镜像翻转布局的元素类型,例如:
①含图标的列表项

②导航栏按钮

③按钮组

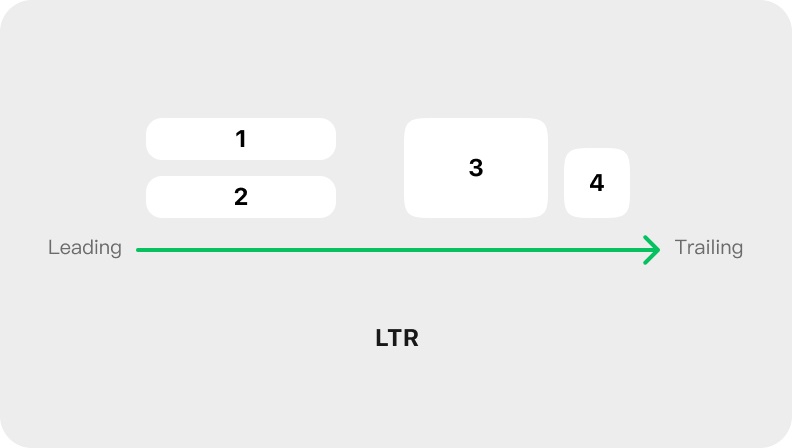
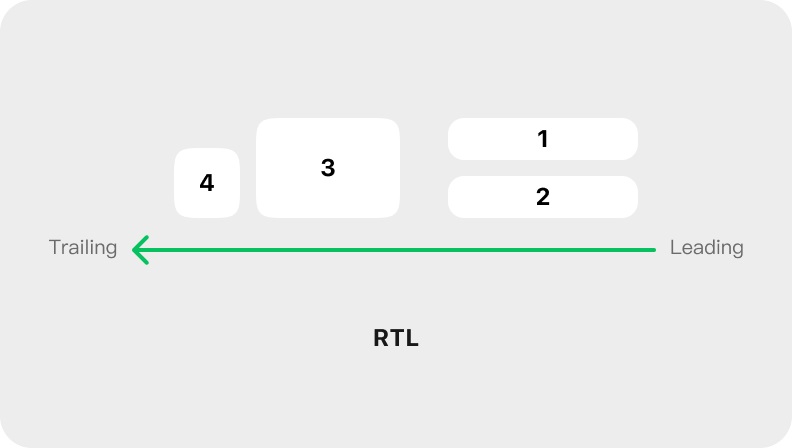
对于需要镜像翻转布局的元素类型,应使用 leading、trailing 属性来描述布局,而不再使用左侧、右侧:
- leading 指的是更接近读写起点的一侧,对于 LTR languages 来说是左侧,对于 RTL languages 来说就是右侧。
- trailing 指的是更接近读写终点的一侧,对于 LTR languages 来说是右侧,对于 RTL languages 来说就是左侧。
使用这组属性后,设备会依据语言的读写方向来自动转译页面布局,以实现正确的读写方向。
2. Universal
指无需处理的元素类型,例如:
①不传达水平方向的图标

②含右手操作含义的图标

③映射物理实体的图标

④图标中的斜杠

⑤媒体进度条

⑥非 RTL 的文本
⑦数据图(X 轴、Y 轴的位置始终不变)
值得注意的是,尽管 RTL 的本文一般使用右对齐,但若文本中穿插有 LTR 语言的段落,此段落仍需保持左对齐,以提高可读性。
3. Dedicated
指需要为每个读写方向分别提供设计的元素类型。
四、语法
对于 UI 中的文本,符合诸如单复数、阴阳性等语法规则是至关重要的。对于静态文本,可以由专业的翻译人员来维护;而对于动态生成的文本,则需要从代码层面来进行「语法自适应」。
语法自适应主要需处理以下 5 点:
1. 标点符号
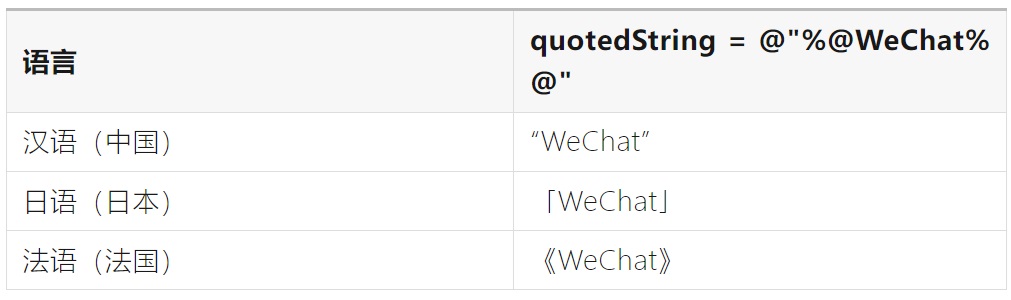
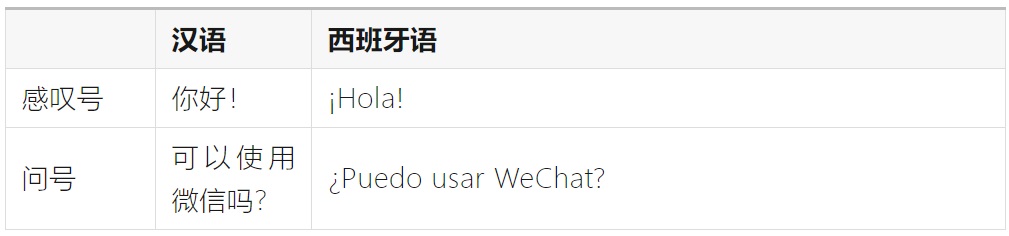
不同的语言可能有不同的标点符号规则,例如:
①样式不同
②位置不同
③某些语言很少使用标点符号

2. 大小写
不同的语言可能有不同的大小写规则,例如:
①某些语言会使用大小写区分含义
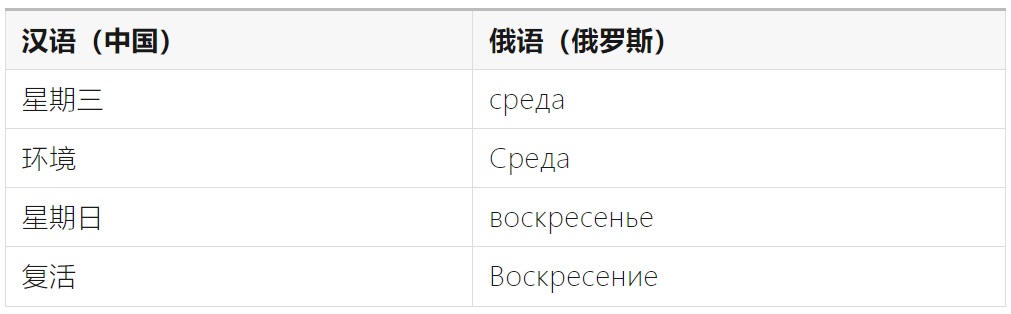
②某些语言没有大小写的概念(如汉语、泰语、阿拉伯语等)
3. 复数
不同的语言可能有不同的处理名词复数形式的规则(pluralization),例如:
①英语仅有 one、other 两种复数形式。

②俄语则拥有更丰富的复数形式。
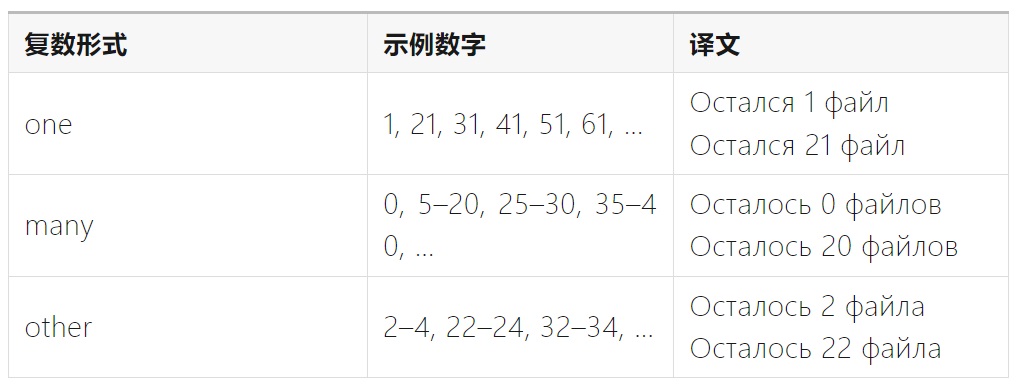
4. 语法性别
语法性别(grammatical gender)指的是,名词、形容词、代词等词性可能会根据所指代的实体的性别(包括 feminine、masculine、neutral)而有所不同。
例如,在西班牙语的外卖点单页中,「份量(tamaño)」的选项应符合用户所选菜品的阴阳性:
- 咖啡(cafe)是阳性的。因此,小份的咖啡应写为「cafe pequeño」。
- 沙拉(ensalada)是阴性的。因此,小份的沙拉应写为「ensalada pequeña」,而不是「ensalada pequeño」
5. 并列结构
并列结构(parallel structure)指的是,在句子中由多个名词、形容词、副词等成分并列放置的结构。
不同的语言可能有不同的并列结构,例如,在英语中,并列结构成分间仅需在插入逗号或「and」即可;但在西班牙语中,「and」一词需根据上下文变为「y」或「e」。
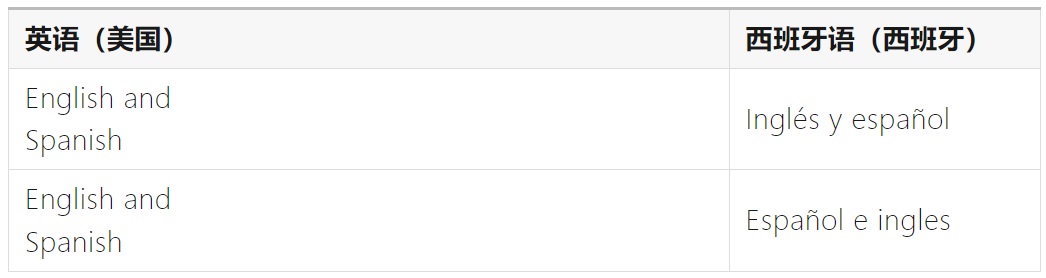
6. 语境敏感性
人们通常会根据对象、话题、场合、文化背景等因素来变化措辞,以生成准确、得体的表达。例如,在汉语中,下级到访用「拜访」,而上级到访则改用「莅临」。
在 UI 中,影响措辞的常见因素为设备类型。设备类型对 UI 文本的影响主要体现以下 2 方面:
①措辞变化
在 iPhone 上,一段文案可能会写为「轻触这里」;而在 iMac 上,这段文案则应写为「点击这里」。
②文案体量
在 iPad 上,一段文案可能会写为「Greetings and Salutations!」,而在 Apple Watch 上,这段文案则可能被缩写为「Hello!」。
iOS、macOS、AndROId 平台均在代码层面提供了语法自适应的解决方案。例如:
- 在 Apple 的平台中,我们可以使用 NSInflectionRule 来自动处理英语复数、时态变化。
- 在 Android 中,我们可以使用 Grammatical Inflection API。
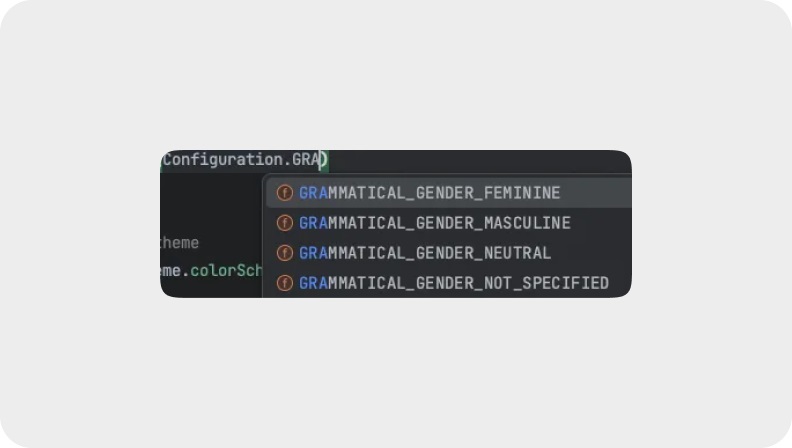
五、数据格式
世界上有着多样的数据格式:表示温度的华氏度、摄氏度,表示长度的中国传统度量衡、国际单位制。UI 中的数据格式应以用户期望的形式显示。
1. 单位制
不同的国家和地区可能有不同的单位制。例如,在美国用的英尺(feet)到法国需转换为米(meter)。
世界上较为通用的单位制有以下 3 种:
- 国际单位制(SI)。适用于绝大部分国家和地区。
- 英制(Imperial Units)。主要用于英国民间、利比里亚、缅甸。
- 美式英制。普遍用于美国。
2. 数字
不同的国家和地区可能有不同的数字类型、书写格式,例如:
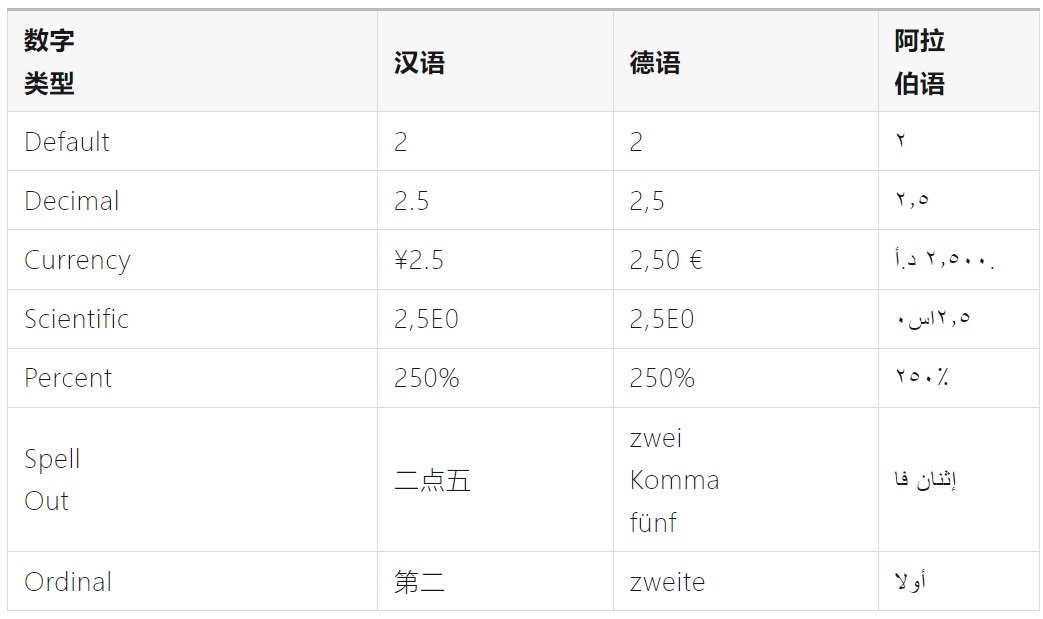
其差异主要在于以下 3 点:
①数字符号(Numeric Notation)
例如,阿拉伯数字符号的「123」,在爪哇语数字符号(Javanese)中写为的「꧑ ꧒ ꧓」。
在 iOS 的锁屏设置中,就提供了多种数字类型供选择。
②十进制分隔符(Decimal Separation)
例如,十进制分隔符在瑞士通常为逗号「,」,但在中国为点「.」。
③数字分组(Number Grouping)
为了更容易阅读位数较大的数字,人们常常会为数字进行分组。在欧洲,通常为三位数一组,但在中国、日本、韩国,则为四位数一组。
3. 货币值
不同的国家和地区可能有不同的币种,这带来了不同的货币值表达方式,例如:
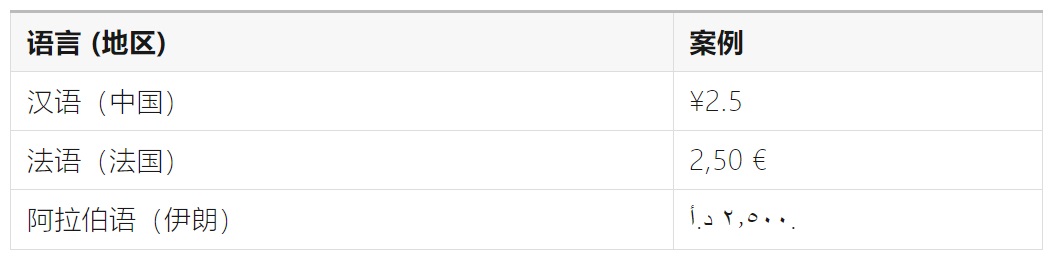
其差异主要在于以下 4 点:
①数字不同
详情请见上文。
②货币符号不同
例如,人民币的符号为「¥」,美元的符号为「$」,欧元的符号为「€」。
③货币符号的位置不同
例如,在日本,货币符号放在数字前(¥200),而法国则不然(200€)。
④货币符号和数值间是否有空格
例如,在美国,货币符号和数值之间没有空格($200),而荷兰则不然(€ 399)。
此外,有些币种的货币符号是相同的。例如:
- 人民币和日元都用「¥」作为货币符号。
- 美元和加拿大元都用「$」作为货币符号。
我们可以使用 ISO 4217 货币代码来解决货币符号相同的问题。例如,将一百元的人民币写为「CNY 100」,将一百元的日元写为「JPY 100」。
值得注意的是,「RMB」「软妹币」「块」「米」均非国际通用的人民币别称,需避免使用。
4. 时间、日期
不同的国家和地区可能有不同的时间、日期格式,例如:
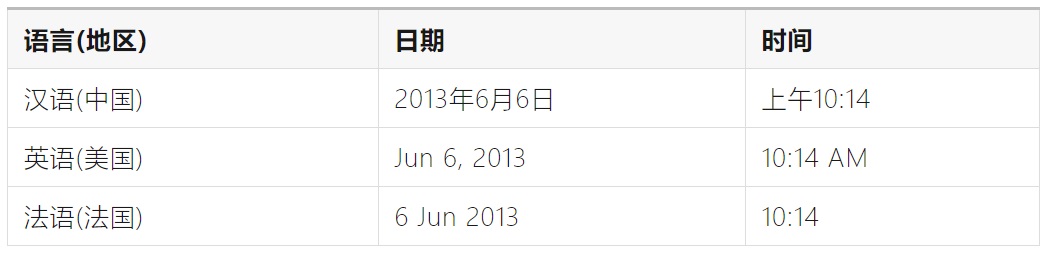

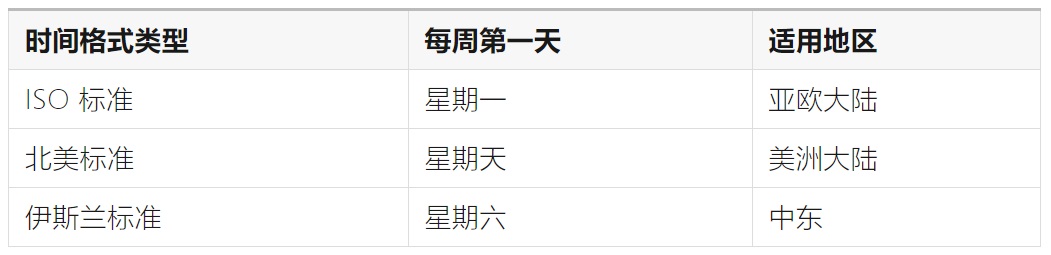
其差异主要在于以下 4 点:
①顺序
大多数欧洲国家使用「DD/MM/YY」格式,美国使用「MM/DD/YY」格式,日本使用「YY/MM/DD」格式。
②分隔符(Separators)
斜杠、破折号、连字符、句点均可能被用作分隔符。
③前导零(Leading Zero)
部份国家和地区会省略前导零,如「2023/6/6」;而其他地区则不然,如「2023/06/06」。
④小时制
12 小时制、24 小时制均可能被使用。
设计策略
①优先使用公历(Gregorian)
以避免产生歧义。也可以直接在页面上对如何理解日期进行说明。
②优先使用「YYYY-MM-DD」格式
因为,这是 ISO 8601 推荐使用的较为清晰的格式。
③支持时区、夏令时,以及本地日历
例如,日本人通常使用皇历(Imperial calendar)来记录生日(如平成 31 年 1 月 1 日),泰国人经常使用佛历(Buddhist calendar)。
5. 电话号码
不同的国家和地区可能有不同的电话号码格式,例如:
- 在法国,电话号码以 2 个数字为 1 组,如「01 23 45 67 89」。
- 在英国,电话号码会被分为 3 组,如「01234 567 789」。
此外,电话号码里可能还会包含国家代码(如英国的国家代码是「+44」)、地区分号(如上海的地区分号是「021」)。
建议将 International Telecommunication Union 的 E.164 standard 用作电话号码格式的标准。
还可以利用 Google 的 libphonenumber 来自动处理电话号码格式。
6. 邮政编码
不同的国家和地区可能有不同的邮政编码格式,例如:
- 中国的邮政编码由 6 个数字组成。
- 美国的邮编由 5 个数字组成。
- 英国的邮编由字母、数字混合而成。
建议将 Universal Postal Union 的 POST*CODE® DataBase 用作邮政编码格式的标准。
7. 地址
不同的国家和地区可能有不同的地址格式,例如:
- 在中国、日本,地址的格式通常为宏观到微观。
- 在美国,地址的格式通常为微观到宏观。
建议将 Universal Postal Union 的 POST*CODE® DataBase 用作地址格式的标准。
8. 人名
不同的国家和地区可能有不同的姓名格式。其差异主要在于以下 5 点:
①顺序
人名的构成顺序可能不同。如:
- 在中国、日本、韩国、匈牙利,人名的顺序通常是「姓、名」,且无空格将其分隔。
- 但在英国,人名的顺序通常是「名、姓」,且有空格将其分隔。
②姓氏
人们可能没有姓氏。
在印度南部、马来西亚、印度尼西亚的一些文化中,许多人的名字只包含一个名字,没有任何姓。
夫妻的姓氏可能不同。
虽然在美国、俄罗斯、日本等国家,妻子改用丈夫的姓氏仍然很常见,但随着女性权益的发展,有越来越多的女性选择婚后不改姓。此外,甚至还有丈夫婚后改用妻子姓氏的情况。
人们可能有多个姓氏。
例如,在「María José Carreño Quiñones」这一西班牙名字中,「Carreño」「Quiñones」都是姓氏。这说明此人可能是「Antonio Carreño Rodríguez」和「María Quiñones Marqués」的女儿。
多个姓氏的顺序可能不同。
例如,西班牙语中,姓氏的顺序是「父姓、母姓」;而在巴西的葡萄牙语中,顺序为「母姓、父姓」。
多个姓氏之间可能会添加短词。
如 Carreño de Quiñones、Tavares e Silva。
③特殊称谓
人们可能有与真名无关的特殊称谓。
例如,在泰国,人们通常有一个常用于非正式场合的昵称。这个昵称也常用于向外国人介绍自己,因为它通常只有 1 到 2 个音节,更易于发音。举个例子,泰国前总理 Thaksin Shinawatra 的昵称是 Maew(แม้ว)。
④词体变形
相同的姓名可能会根据性别产生词体变形。
例如,对于「Patronymic」这一冰岛名,用于男性时会以 -son 结尾,而用于女性时会以 -dóttir 结尾。
⑤多音字
相同的姓名可能会有不同的发音。
以日本人名为例。日本人名中的汉字(kanji characters)通常有多种发音。这可能使得人们难以确切地知道如何读一个名字,并且也给给予发音的排序、检索带来困难。例如,「東海林賢蔵」这一姓氏可以被读为「Tōkairin」,也可以读为「Shōji」。
由此,人们会将日本人名转换为用罗马字母拼写的形式,以便于非日语使用者更好地理解日本人名的发音和拼写。但转为罗马化(kanji romanization)后的日本人名仍有相同发音带来的问题。例如,「庄司」「庄子」「東海林」「小路」罗马化后都是「Shōji」。
设计策略
- 允许输入特殊字符。应允许用户输入连字符、撇号、空格等特殊字符。
- 允许不填写姓氏。若将姓氏作为必填项,没有姓氏的用户会在此字段中输入垃圾数据(如「.」或「Mr.」)以勉强完成表格填写。
- 支持设置称呼。在设置个人资料时,建议单独询问用户希望应用如何称呼他们。例如,对于中国人名「李晓月」,「李女士」「李小姐」「小李」「晓月」都是可能被期望的称呼。
- 支持设置发音。鉴于多音字的存在,应支持用户声明人名的正确发音。
- 支持多种排序方式。因为,人们不总是期望按姓氏排序联系人。例如,泰国、冰岛人希望按名字排序。
- 考虑仅提供一个足够空间的全名输入框。因为,来自不同文化的姓名的长度、构成、顺序都是不同的。仅要求填写一个姓名字短能减少大量适配工作,并提升灵活性。
总的来说,我们应尽可能遵循由「Unicode CLDR Project」提供的规范。
值得注意的是,使用相同语言的用户不一定会使用相同的数据格式。例如:一个生活在德国的以英语为母语的用户,可能会选择英语作为语言,选择德国作为地区。
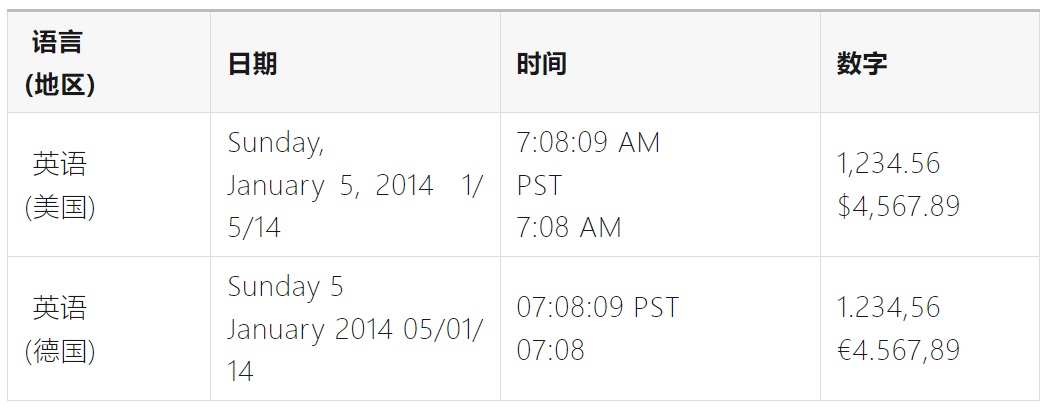
因此,UI 应支持分别选择语言、数据格式类型,以支持用户的多样化诉求。
六、设计验收
1. 使用 Pseudolanguages
对于多语言的页面呈现,我们推荐使用 Pseudolanguages(伪语言)进行验收。
Pseudolanguages 并不是真实存在的语言,而是一种模拟其他语言的特征和特性的语言。通过在 UI 中使用 pseudolanguages,我们可以测试应用在不同语言环境下的适应性和可用性。

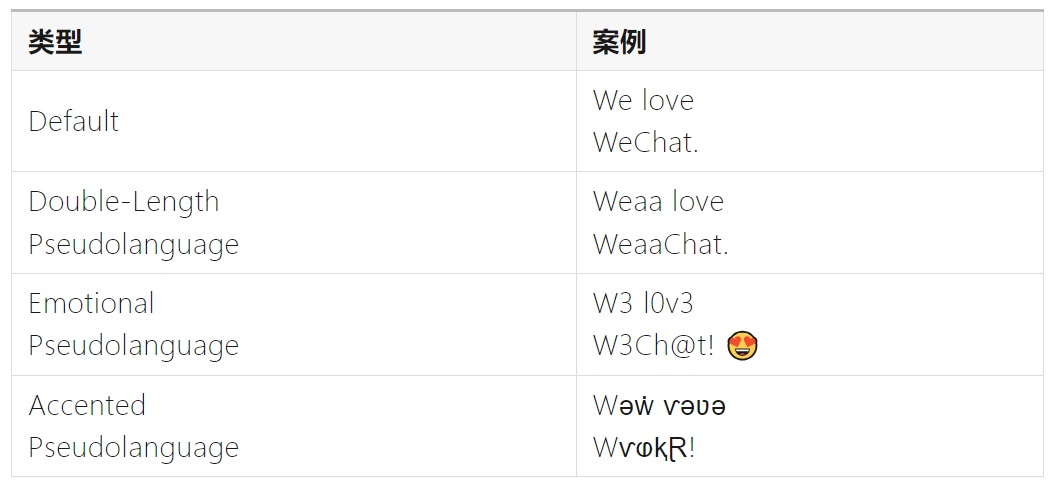
在 Xcode 中,我们可以使用以下 6 种 pseudolanguages 进行验收:
①Double-Length Pseudolanguage
将文本长度加倍,以测试应用在长文本环境下的效果。
②Right-to-Left Pseudolanguage
将语言方向改成从右往左,以测试应用在从右到左的语言环境下的效果。
③Emotional Pseudolanguage
将文本转换成 emoji 等利于传达情感的形式。
④Accented Pseudolanguage
将文本转换成带有重音符号(accents)的文本,以测试应用在带有高低升降调的语言环境下的效果。
⑤Bounded String Pseudolanguage
在字符串两端加上中括号,以便识别出可能出现截断的字符串。
⑥Right-to-Left Pseudolanguage With Right-to-Left Strings
将语言方向改成从右往左,并在其中穿插右到左的文本。
以下是将「We love WeChat!」这一语句转为部份类型的 pseudolanguages 的效果:
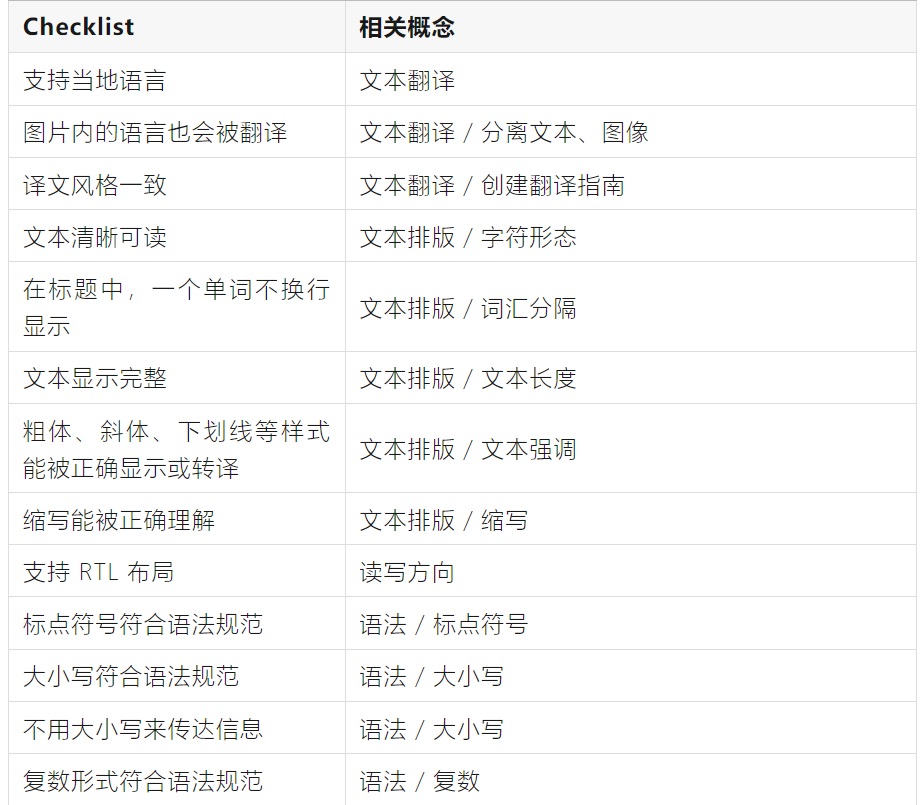
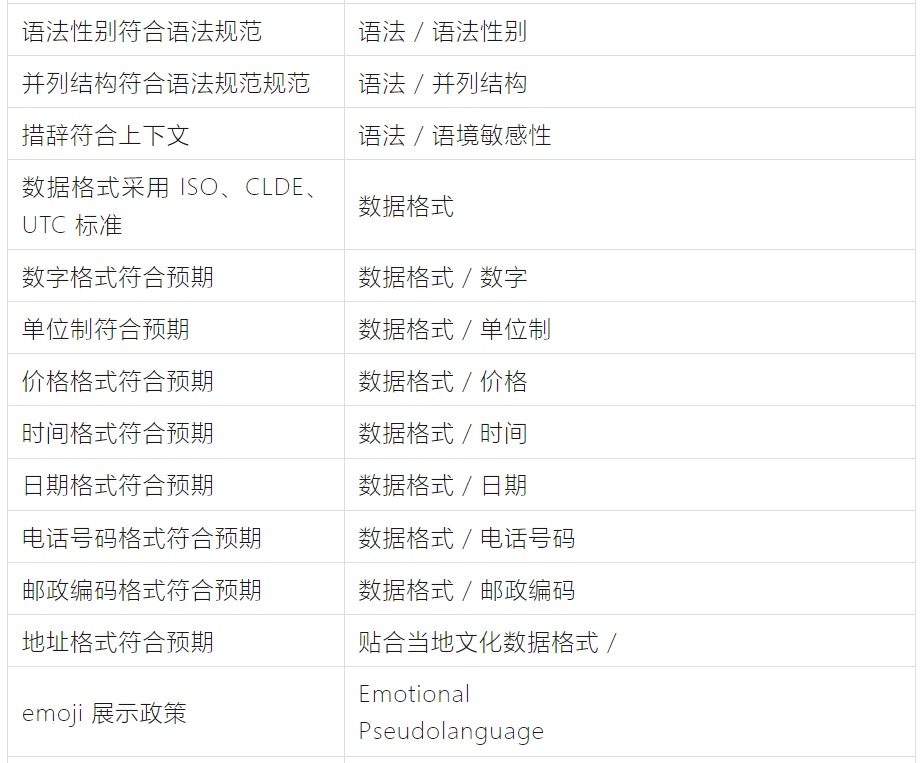
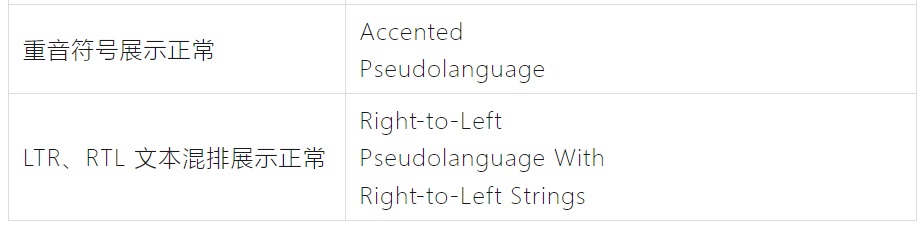
2. Checklist
以下 checklist 仅供参考,可以根据实际需求进行调整。
结语
通过全球化的设计,我们将朝着对全球用户更具同理心的目标迈出重要一步。我们希望能有更多设计师能参与到设计支持全球语言的 UI 的工作中来,让科技不再限于特定文化。
作者:We-Design


